09 novembre 2022
La figura del Data Engineer: il governo di algoritmi e dati
Una figura che sta diventando sempre più determinante per le organizzazioni complesse: ecco l'identikit.
Per la figura del Data Engineer, algoritmi, dati e la loro gestione è il pane quotidiano. Chiunque giornalmente si occupa di dati e ne conosce le potenzialità, sa che da diversi decenni la loro analisi è un ambito cruciale per il business. È uno dei fondamenti della digital transformation guidata dai big data e dalle tecnologie che ruotano intorno ad essi e che comprende la possibilità di analizzare i dati per estrarne insight di valore.
Negli ultimi anni, col crescere della complessità, sono nate nuove figure professionali specializzate su specifici ambiti tecnologici. Il loro scopo è sfruttare al meglio strumenti e metodologie diverse nella gestione dei dati. Per questo sta diventando sempre più rilevante la figura del Data Engineer.
Identikit della Figura del Data Engineer
Il Data Engineer è un ingegnere del software che si è specializzato su algoritmi e architetture dedicate alla movimentazione, manipolazione e gestione dei dati.
È un professionista che ha il compito di progettare, realizzare e mantenere, interfacce e meccanismi per l’accesso ai dati aziendali. E ne garantisce fruibilità, archiviazione e integrità.
Al Data Engineer sono richieste competenze di business intelligence, machine learning, tecnologie Big Data e linguaggi di programmazione particolarmente adatti alla manipolazione dei dati come Python, Java o Scala. Ciò gli consente di andare oltre le competenze tipiche dell’ingegnere del software ossia di pianificazione, progettazione e implementazione di software avanzati. A queste caratteristiche non può mancare anche tanta creatività e flessibilità e in generale un approccio fortemente innovativo.
Il suo ruolo infatti richiede poliedricità, in quanto ha la necessità di acquisire competenze di vario genere:
hard skill tecniche e molto specifiche per affrontare una quantità e una varietà di dati sempre crescente, insieme ad un crescente numero di applicazioni che li consumano.
soft skill comunicative e cross funzionali per interagire proficuamente con le altre figure professionali del mondo dei dati.
Evoluzione del Ruolo (nel mondo e in Cerved)
In Cerved, all’interno dell’area di Software Engineering, sono presenti diversi team specializzati in attività di Data Engineering. Si occupano della progettazione e della realizzazione di “Data Pipeline”, ovvero vere e proprie filiere che raccolgono ed elaborano dati grezzi per restituire valore aggiunto ai clienti.
Le Data Pipeline si possono dividere in due macro categorie:
batch-oriented: dedicate a flussi di dati predittivi, da elaborare in un periodo di tempo prestabilito su un volume di dati elevato.
streaming-oriented: dedicate a flussi event-driven, riferiti a flussi di elaborazione real-time o near real-time su un volume di dati non predefinito.
Nonostante le differenze tra le due categorie, si possono realizzare per entrambe dei flussi lavoro suddivisibili in fasi separate. Eccole: data gathering (acquisizione del dato), data cleansing (rilevamento e correzione dei dati), data processing (deduplicazione, standardizzazione e verifica), data catalog (inventario dei dati) e infine quella di data exposition (erogazione) attraverso opportune API/Microservizi o Dashboard.

Mansioni e ruolo in Cerved
Il Data Engineer in Cerved, è una figura di collegamento indispensabile tra i consumatori dei dati (data analyst, data scientist, data owner) e i produttori dei dati. Sebbene queste figure siano altamente specializzate e con forti skill tecniche, è importante che vi sia una comunicazione buona e efficace. È fondamentale che il data engineer riesca a condividere con le parti interessate la cultura dei dati, le regole che si creano dietro questi ultimi. Il fine è di condividere “buone pratiche” che diventino abilitanti e migliorino la produttività.
Tra le mansioni dei Data Engineers vi sono attività di:
- sviluppo software e di progettazione di architetture, che siano in linea con i requisiti di business.
- ottimizzazione, per migliorare l’affidabilità e la qualità dei dati.
- analisi, al fine di identificare pattern e contribuire alla realizzazione di sistemi di apprendimento automatico (machine learning) mirati a migliorare la qualità dei dati.
Anche il modello organizzativo contribuisce all’empowerment della figura del Data Engineer. In Cerved si evita quanto più possibile di inserire figure di intermediazione. Al nostro interno infatti, i Data Engineer interagiscono direttamente con le parti interessate, così da rendere l’intero processo più fluido e facilitando la comprensione delle caratteristiche dei dati da elaborare.
Esempi di dati/progetti in Cerved
In Cerved elaboriamo milioni di dati. Sui nostri database sono presenti oltre 1,1 Petabyte dai quali è possibile estrarre informazioni su oltre 5,6 Milioni di aziende.
I dati vengono archiviati sul nostro data lake, dal quale si alimentano database di vario tipo: relazionali e non relazionali.
Tra i molteplici progetti che vengono portati avanti in Cerved ogni giorno, alcuni presentano sfide legate al mondo dei Big Data. Come ad esempio l’intero flusso di approvvigionamento dei dati legati al prodotto PayLine che è particolarmente data intensive. Questo è stato il primo progetto sviluppato su piattaforma Hadoop. E’ interamente sviluppato in Scala, usando una delle primissime versioni del framework open source Spark, dedicato all’ elaborazione parallela, in memory per l’analisi di Big Data.
All’interno del progetto PayLine, le contribuzioni contabili dei nostri clienti sono memorizzate sul nostro data lake e a seguire si attivano le pipeline di rielaborazione che trasformano i dati. I dati vengono poi normalizzati, memorizzati sul data lake e trasferiti sui nostri database Oracle di erogazione. Qui vengono utilizzati per realizzare molteplici tipi di prodotti per i nostri clienti.
Negli ultimi anni, inoltre, è stata avviata un’evoluzione tecnologica all’interno del mondo dati che ha rappresentato una sfida per la figura del DataEngineer. In particolare è cambiato il modo in cui i dati vengono importati/propagati all’interno del mondo Cerved migrando da un’architettura batch based a un’architettura Streaming.
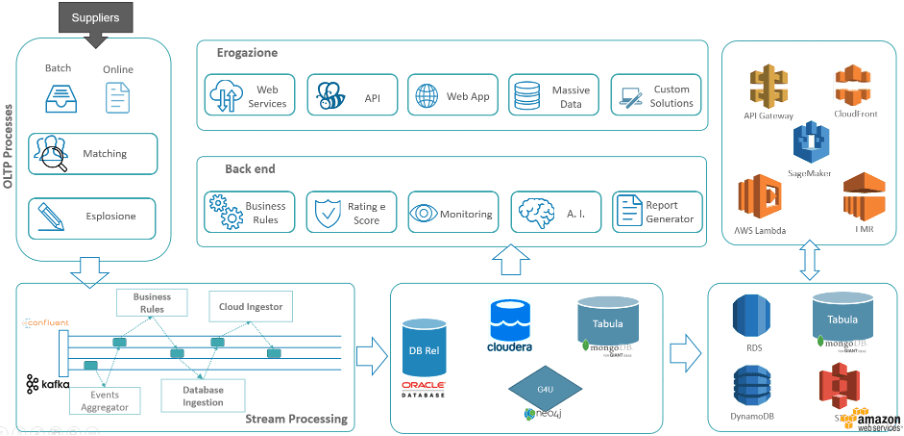
Con l’introduzione del progetto BigDataPlatform (schematizzato nell’immagine sottostante), i dati vengono gestiti e propagati da processi streaming (implementati su tecnologia kafka) in modo da convogliare tutti le informazioni su un unico punto di erogazione/propagazione.
Le informazioni che transitano sulla BigDataPlatform sono arricchite di tutte le regole, logiche e algoritmi. Queste ne permettono la fruibilità sui vari prodotti, evitando così la duplicazione delle stesse logiche che inevitabilmente può introdurre distonie.
Le medesime informazioni verranno poi propagate e depositate su una serie di database “periferici” ognuno dei quali ottimizzato per uno specifico contesto di utilizzo. MongoDb per erogazione documentale, neo4 per implementazione di algoritmi di network analisys etc stc.
Di seguito è mostrata l’architettura a tendere in Cerved: non più Oracle come punto di partenza del dato, ma una produzione continua di eventi con vari agenti sottoscrittori. Questi tramite meccanismi di streaming verso Oracle, MondoDB, Neo4J e altre strutture mirate provvedono alla riorganizzazione dei dati e all’erogazione verso i nostri clienti:
Cerved al Codemotion 2021
Negli ultimi anni il Cloud è diventata una delle tecnologie che sta apportando diversi benefici anche nel mondo della Data Engineering.
Il Cloud ha rivoluzionato il modo di analizzare e gestire i dati, abilitando di fatto nuove tendenze nella gestione e manipolazione di questi ultimi, suggerendo nuovi percorsi di business data driven.
I Cloud Providers hanno portato una ventata di innovazione, semplificando e rendendo l’accesso ai dati sempre più veloce ed efficace.
Questa evoluzione tecnologica ha richiesto molti cambiamenti nel modo di gestire i dati.
Cerved ha seguito questa evoluzione. Il prossimo 10 Novembre presenterà al Codemotion di Milano un esempio di come la collaborazione fra Data Scientist e Data Engineer abbia permesso di realizzare sul cloud una Data Pipeline di tipo streaming per l’arricchimento semantico di testi non strutturati.
Cerved racconterà come sviluppare, con l’aiuto di strumenti cloud, modelli di Machine Learning per l’analisi dei testi. E inoltre, come effettuare il deploy e realizzare una pipeline di arricchimento dei dati in modalità Serverless in near real-time.
© 2025 Cerved Group S.p.A. u.s.
Via dell’Unione Europea n. 6/A-6/B – 20097 San Donato Milanese (MI) – REA 2035639 Cap. Soc. € 50.521.142 – P.I. IT08587760961 – P.I. Gruppo IT12022630961 - Azienda con sistema qualità certificato da DNV – UNI EN ISO 9001:2015