I dati sono la forza trainante del continuo successo di Cerved, rappresentano la materia prima e le informazioni sono il prodotto finale.
Disponiamo di quasi 1,1 PB di dati archiviati ed abbiamo implementato negli anni una vasta gamma di architetture e tecnologie per gestirli.
Cerved nasce oltre cinquanta anni fa ed è cresciuta sia con prodotti e servizi interni che con acquisizioni, questo ha fatto sì che l’architettura dati non sia cresciuta in maniera organica bensì per integrazioni tra componenti vecchi e nuovi più parti di aziende acquisite.
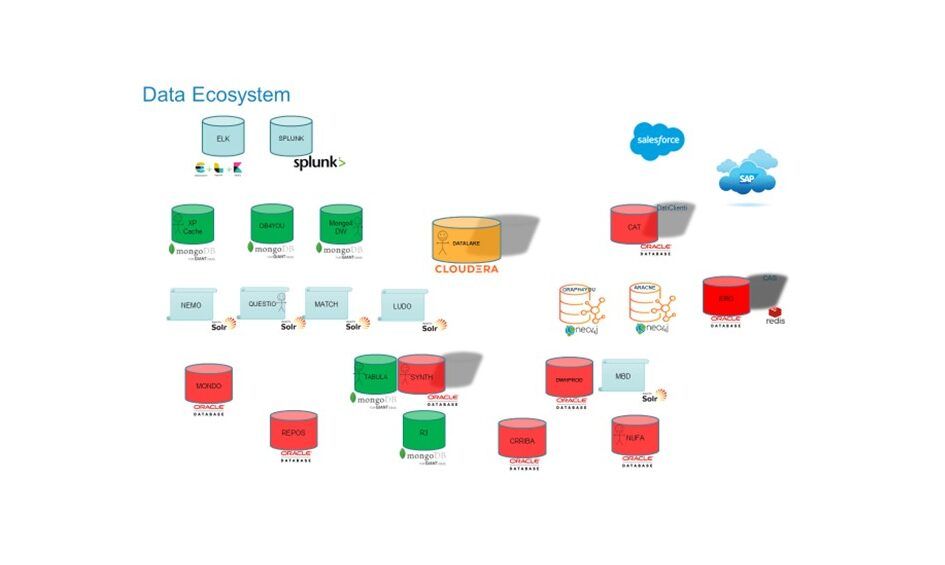
Il nostro ecosistema dati attuale è molto articolato, le principali tecnologie ed architetture sono:
– Una IaaS (Infrastructure as a Service) su cloud Oracle OCI, gli elementi principali sono degli Oracle RAC 19c ospitati su macchine ingegnerizzate ExaCs (Exadata Cloud Service) che gestiscono i nostri principali database operazionali, i quali a loro volta alimentano buona parte delle piattaforme dati descritte nei punti seguenti, tutti i nostri database Oracle ad oggi sono in versione 19c;
– MySQL RDS Aurora in versione 8 ospitato su cloud AWS dove utilizziamo servizi SaaS (Software as a Service) per gli ambienti di sviluppo e collaudo che PaaS (Platform as a Service), sui nostri MySQL girano database sia di applicativi interni che di applicazioni i cui dati per lo più non vengono poi propagati su altre basi dati per essere riutilizzati da altre applicazioni;
– MongoDB in versioni dalla 6 in giù con architetture IaaS, PaaS e SaaS (Mongo Atlas) sempre ospitati su AWS, questa tecnologia è utilizzata prevalentemente per i nostri report di BI (Business Information);
– I database a grafo sono su tecnologia Neo4j versione 4 ed il caso d’uso principale è individuare i legami tra titolari di azienda, l’architettura è un cluster IaaS su AWS,
– il Data Lake dove confluiscono dati strutturati e non basato su tecnologia Cloudera, anch’esso migrato su cloud AWS utilizza un’architettura IaaS;
– le piattaforme di ricerca testuale basate su Splunk ed ELK: sono usate per le nostre dashboard di moniroting; per le funzionalità di search nelle applicazioni Cerved sono usati anche cluster Solr, con uso di funzioni di aggregazione dati complessi;
– completano il quadro sistemi di caching come Redis.
Fino a qualche anno fa l’aggiornamento e la sincronizzazione di tutte queste base dati, insieme all’integrazione di quelle derivanti dalle acquisizioni, ci ha portato a realizzare un intricato sistema di job Etl difficile da gestire ma anche da espandere quando nasceva un nuovo prodotto con una nuova base dati.
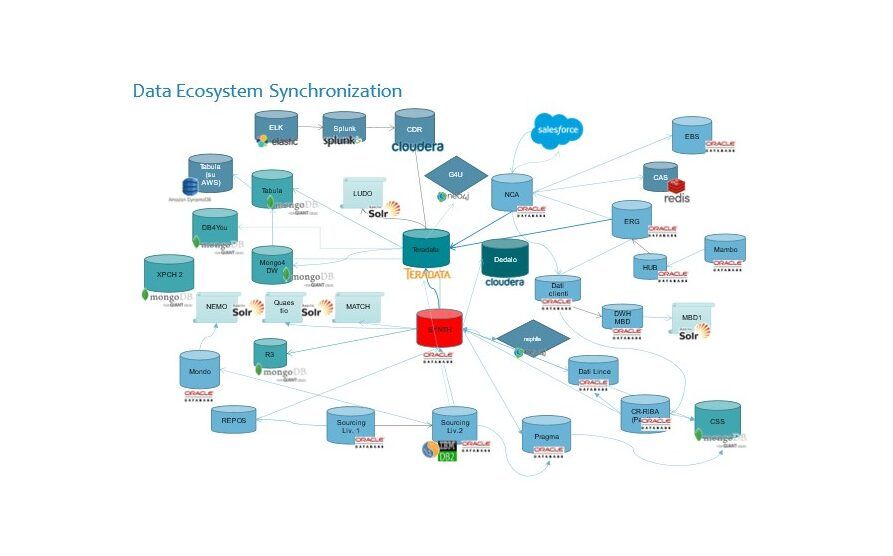
Questo perché non avendo un sistema di distribuzione delle modifiche siamo stati costretti a creare dei riversamenti di dati peer to peer tra le varie basi dati che contenevano la modifica e quelle che dovevano riceverla per restare in synch. La figura sopra chiarisce bene il complicato intreccio di job ETL che reggevano la sincronizzazione.
Ecosistema di dati Cerved: cluster Confluent Kafka
Nel 2017 abbiamo progettato ed implementato una nuova architettura dati basata sugli eventi, il cui sistema di trasmissione è costituito da un cluster Confluent Kafka che ci ha garantito soluzioni smart e agile per distribuire e sincronizzare le modifiche in tutto il nostro ecosistema dati, quindi il processo di propagazione e sincronizzazione è diventato uno e centralizzato.
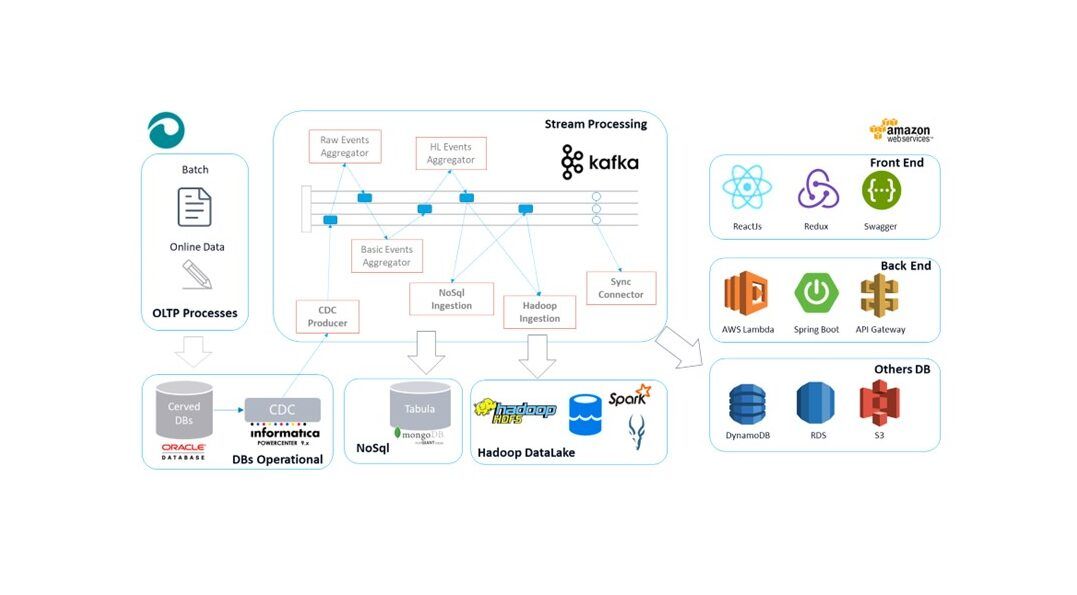
Scendendo in dettaglio le fasi di questa architettura partono dallo strumento Change Data Capture di informatica per intercettare tutti gli eventi relativi alla modifica dei dati sulla fonte principale, rappresentata dai database Oracle; ogni qualvolta CDC pubblica una modifica su una coda Kafka (Publisher), in breve tempo tutte le altre piattaforme dati che sono in ascolto su queste code (Consumers) diventano consapevoli del cambiamento e possono allinearsi in maniera proattiva. È facile capire che la complessità della soluzione precedente è stata drasticamente ridotta con questo nuovo approccio, niente più job da pianificare e mantenere, niente più lunghi tempi di attesa per allineare tutto, infine un solo punto per propagare tutte le modifiche dei dati.
Circa tre anni fa abbiamo deciso di migrare tutti i nostri dati e applicazioni nel cloud, i cui dettagli sono descritti in questo articolo (leggi il nostro approfondimento “In viaggio verso il cloud. L’esperienza Cerved con AWS” per saperne di più).
Nell’ultimo anno abbiamo migrato anche la piattaforma Confluent Kafka, ma invece di una strategia lift-and-shift abbiamo scelto di adottare il servizio gestito Confluent Cloud per passare da un’architettura self managed ad un PaaS: vediamo le fasi principali di questo percorso.
Connessione al Cloud
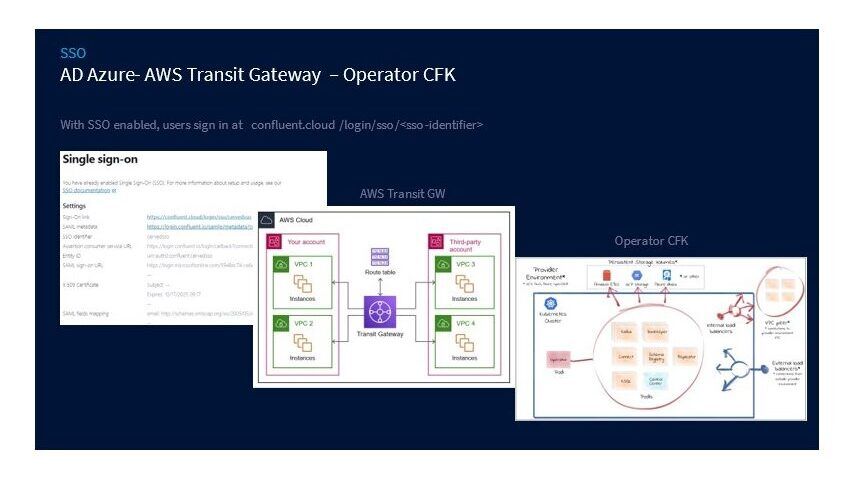
Come primo step, abbiamo configurato il Single Sign On per garantire agli utenti sicurezza e governance. La configurazione ha coinvolto diversi componenti, i principali sono: Active Directory su Azure, Transit Gateway su AWS e l’Operator Confluent per Kubernetes.
Strategia di migrazione: cluster Linking
Realizzato il cluster in cloud ed i protocolli di comunicazione ed autenticazione abbiamo adottato il principale strumento offerto da Confluent per la migrazione da on-premise a Confluent Cloud ovvero il Cluster Linking, il quale consente di replicare automaticamente le code su un altro cluster, incluso i dati e la sincronizzazione costante tra il cluster on-premise e quello su Confluent Cloud.
Questo aspetto ha abbattuto significativamente la complessità della migrazione e della sincronizzazione dei dati, consentendoci di eseguire vari test per abbattere il principale ostacolo a qualunque migrazione in cloud, la data gravity. In sostanza, avendo un cluster allineato sulla piattaforma target, abbiamo eseguito numerosi test per misurare l’impatto della latenza, a sua volta aumentata dallo spostamento fisico dei dati dal nostro data center on-premise di Padova al cloud AWS nella regione di Milano.
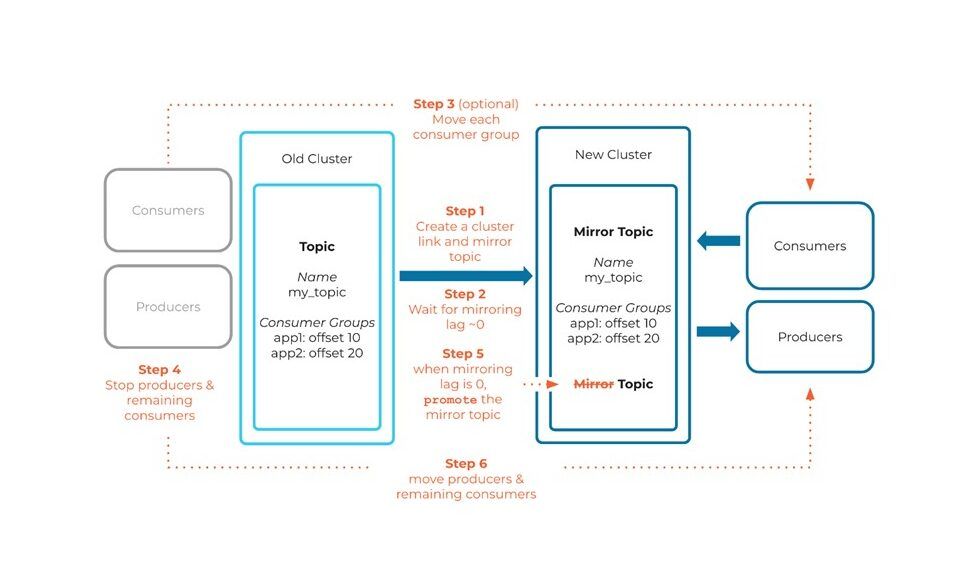
Strategia di migrazione in cinque passi
Di seguito un grafico che descrive in maniera schematica come abbiamo affrontato i vari step di migrazione delle code e delle applicazioni che agiscono da Producers e Consumers durante la migrazione del cluster Kafka dalla piattaforma on-premise a quella su Confluent Cloud.
Cosa abbiamo ricavato dalla migrazione su Confluent Cloud
Il passaggio su Confluent Cloud ha prodotto una serie di vantaggi che possiamo sintetizzare in questi punti:
• Alta affidabilità, Confluent Cloud dichiara uno SLA di disponibilità del 99,99%
• Sicurezza aumentata grazie ai protocolli implementati
• Adeguamento dinamico delle prestazioni in base ai workload, grazie alla scalabilità automatica della piattaforma che consente di adeguare la potenza di calcolo e le risorse necessarie in base ai carichi del cluster
• Contenimento dei costi di infrastruttura e manutenzione
• Supporto 24/7
• Disaster recovery costantemente sincronizzato grazie al Cluster Linking.
© 2026 Cerved Group S.p.A. u.s.
Via dell’Unione Europea n. 6/A-6/B – 20097 San Donato Milanese (MI) – REA 2035639 Cap. Soc. € 50.521.142 – P.I. IT08587760961 – P.I. Gruppo IT12022630961 - Azienda con sistema qualità certificato da DNV – UNI EN ISO 9001:2015